


Tu Primer Agente de IA: Más Sencillo de lo que Crees
La guía completa (con código).

Tu Primer Agente de IA: Más Sencillo de lo que Crees
Por: Nir Diamant, esta es una traducción de un popular post (véase el original) que ha escrito en su newsletter DiamantAI, y que tiene el objetivo de proporcionar a la gente un acceso sencillo a todo lo nuevo que surja, bien explicado y con tutoriales de código. 💎
Después de trabajar en numerosos casos de uso de agentes de IA y de organizar un hackatón global, con LangChain, con participantes de todo el mundo, para crear agentes únicos, me tomé el tiempo de escribir esta entrada para que el concepto de agentes de IA sea fácil de entender.
En esta entrada, explicaré qué son los agentes de IA y te guiaré a través de un ejemplo sencillo para ayudarte a construir tu primer agente fácilmente usando LangGraph.
Empecemos con una introducción
El mundo de la inteligencia artificial está experimentando una profunda transformación. Durante años, hemos construido modelos especializados de IA, cada uno diseñado para sobresalir en una tarea específica. Tenemos modelos que pueden escribir texto, otros que pueden analizar sentimientos y otros que pueden clasificar documentos. Estos modelos son como especialistas cualificados, cada uno desempeñando su función particular con una experiencia impresionante. Pero algo ha faltado: la capacidad de coordinar estas capacidades, de entender el contexto y de tomar decisiones sobre qué hacer a continuación.
Piensa en cómo un experto humano aborda una tarea compleja. Cuando un detective investiga un caso, no se limita a recopilar pruebas de forma aislada. Entrevista a los testigos y, en función de lo que averigüe, decide qué pistas seguir a continuación. Puede que note una contradicción que le haga volver a examinar pruebas anteriores. Cada dato influye en sus siguientes pasos, y mantiene una imagen completa de la investigación en su mente.

Agentes de IA
Este enfoque fragmentado de la IA creó importantes desafíos. Supuso una pesada carga para los usuarios gestionar flujos de trabajo complejos, se perdió un valioso contexto entre los pasos y faltó la adaptabilidad necesaria para las tareas del mundo real. Cada modelo funcionaba de forma aislada, como especialistas que no podían comunicarse entre sí ni ajustar su trabajo en función de lo que descubrían sus colegas.
Aquí es donde los agentes de IA revolucionan el panorama. Representan un cambio fundamental en la forma en que abordamos la inteligencia artificial. Un agente actúa más como un coordinador experto, orquestando múltiples capacidades mientras mantiene una comprensión holística de la tarea. Puede tomar decisiones informadas sobre qué hacer a continuación basándose en lo que aprende a lo largo del camino, de forma muy similar a como lo haría un experto humano.
¿Qué hace diferente a un agente de IA?
Para entender esta transformación, examinemos cómo los agentes manejan una tarea específica: analizar un artículo de investigación sobre un nuevo tratamiento médico.
Un enfoque tradicional de IA fragmenta el análisis en pasos aislados: resumir el artículo, extraer términos clave, categorizar el tipo de investigación y generar ideas. Cada modelo realiza su tarea de forma independiente, ajeno a los hallazgos de los demás. Si el resumen revela que la metodología del artículo no está clara, no hay forma automatizada de volver atrás y examinar esa sección con más cuidado. El proceso es rígido, predeterminado y a menudo pasa por alto conexiones cruciales.
Un agente de IA, sin embargo, aborda la tarea con la adaptabilidad de un investigador humano. Puede comenzar con una visión general, pero puede ajustar dinámicamente su enfoque en función de lo que descubre. Cuando encuentra detalles metodológicos significativos, puede optar por analizar esa sección más a fondo. Si encuentra referencias intrigantes a otras investigaciones, puede marcarlas para investigarlas más a fondo. El agente mantiene una comprensión completa del artículo mientras guía activamente su análisis en función de los conocimientos emergentes.
Este enfoque dinámico y consciente del contexto representa la diferencia clave entre la IA tradicional y los agentes. En lugar de ejecutar una secuencia fija de pasos, el agente actúa como una guía inteligente a través del análisis, tomando decisiones estratégicas basadas en todo lo que aprende a lo largo del camino.
La arquitectura de la inteligencia
En esencia, los agentes de IA se basan en varios principios fundamentales que permiten este enfoque más sofisticado de la resolución de problemas.
En primer lugar, está el concepto de gestión de estados🗂️. Piensa en esto como la memoria de trabajo del agente: su capacidad para mantener el contexto sobre lo que ha aprendido y lo que está tratando de lograr. Al igual que un investigador humano tiene en cuenta todo el caso mientras examina las pruebas individuales, un agente mantiene la conciencia de su tarea general mientras realiza operaciones específicas.
Luego está el marco de toma de decisiones⚖️. No se trata solo de elegir entre opciones predeterminadas, sino de comprender qué herramientas y enfoques están disponibles y seleccionar los más adecuados en función de la situación actual. Es similar a cómo un detective podría decidir si interroga a otro testigo o analiza pruebas físicas basándose en lo que ha aprendido hasta ahora.
Por último, está la capacidad de utilizar herramientas🧰 de manera eficaz. Un agente no solo tiene acceso a diferentes capacidades, sino que entiende cuándo y cómo utilizarlas. Es como un artesano que no solo sabe de qué herramientas dispone, sino cuándo es más apropiada cada una y cómo combinarlas eficazmente.
Entender LangGraph, un marco para el flujo de trabajo de los agentes de IA
Ahora que entendemos qué son los agentes de IA y por qué son transformadores, exploremos cómo construir uno. Aquí es donde LangGraph entra en escena. LangGraph es un marco de trabajo de LangChain que proporciona la estructura y las herramientas que necesitamos para crear sofisticados agentes de IA, y lo hace a través de un potente enfoque basado en grafos.
Piensa en LangGraph como en la mesa de dibujo de un arquitecto: nos da las herramientas para diseñar cómo pensará y actuará nuestro agente. Al igual que un arquitecto dibuja planos que muestran cómo se conectan las diferentes habitaciones y cómo fluirá la gente a través de un edificio, LangGraph nos permite diseñar cómo se conectarán las diferentes capacidades y cómo fluirá la información a través de nuestro agente.
El enfoque basado en gráficos es particularmente intuitivo. Cada capacidad que tiene nuestro agente se representa como un nodo en el gráfico, como las habitaciones de un edificio. Las conexiones entre estos nodos, llamadas bordes, determinan cómo fluye la información de una capacidad a otra. Esta estructura facilita la visualización y modificación del funcionamiento de nuestro agente, al igual que el plano de un arquitecto facilita la comprensión y modificación del diseño de un edificio.
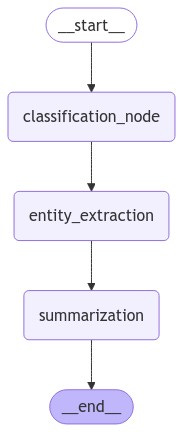
un ejemplo de un agente LangGraph (¡que vamos a implementar!)
Creación de nuestro primer agente: un sistema de análisis de texto
Pongamos en práctica estos conceptos creando un agente que pueda analizar documentos de texto. Nuestro agente será capaz de entender el tipo de texto que está viendo, identificar la información importante que contiene y crear resúmenes concisos. Es como crear un asistente de investigación inteligente que puede ayudarnos a entender documentos de forma rápida y exhaustiva.
Puedes encontrar el código completo en mi repositorio GitHub (6K⭐), junto con otros 42 tutoriales sobre la creación de varios agentes de IA, clasificados por nivel de dificultad y tipo de caso de uso:
Configuración de nuestro entorno
Antes de sumergirnos en el código, configuremos correctamente nuestro entorno de desarrollo. Esto solo llevará unos minutos y garantizará que todo funcione correctamente.
Crea un entorno virtual Primero, abre tu terminal y crea un nuevo directorio para este proyecto:
bash
mkdir ai_agent_project cd ai_agent_projectCrea y activa un entorno virtual:
bash
# Windows
python -m venv agent_env agent_env\Scripts\activate
# macOS/Linux
python3 -m venv agent_env source agent_env/bin/activateInstalaa los paquetes necesarios Con tu entorno virtual activado, instala los paquetes necesarios:
bash
pip install langgraph langchain langchain-openai python-dotenvConfigura tu clave API de OpenAI Necesitarás una clave API de OpenAI para utilizar sus modelos. A continuación te explicamos cómo conseguir una:
Crea una cuenta o inicia sesión
Navega hasta la sección Claves API
Haz clic en «Crear nueva clave secreta».
Copia tu clave API.
Ahora crea un archivo .env en el directorio de tu proyecto:
bash
# Windows
echo OPENAI_API_KEY=your-api-key-here > .env
# macOS/Linux
echo "OPENAI_API_KEY=your-api-key-here" > .envNota: “your-api-key-here” puede ser “tu-clave-api-aquí”.
Sustituye «your-api-key-here» por tu clave API de OpenAI real.
Crear un archivo de prueba Vamos a asegurarnos de que todo funciona. Crea un archivo llamado
test_setup.py:
python
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
# Load environment variables
load_dotenv()
# Initialize the ChatOpenAI instance
llm = ChatOpenAI(model="gpt-4o-mini")
# Test the setup
response = llm.invoke("Hello! Are you working?") print(response.content)Ejecútalo para verificar tu configuración:
bash
python test_setup.pySi ves una respuesta, ¡enhorabuena! Tu entorno está listo para funcionar.
Ahora que todo está listo, comencemos a crear nuestro agente. Primero, necesitamos importar las herramientas que usaremos:
import os
from typing import TypedDict, List
from langgraph.graph import StateGraph, END
from langchain.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from langchain.schema import HumanMessageCada una de estas importaciones desempeña un papel crucial en la funcionalidad de nuestro agente. La clase StateGraph proporcionará la base para la estructura de nuestro agente, mientras que PromptTemplate y ChatOpenAI nos brindan las herramientas para interactuar con modelos de IA de manera efectiva.
Diseño de la memoria de nuestro agente
Al igual que la inteligencia humana requiere memoria, nuestro agente necesita una forma de hacer un seguimiento de la información. Creamos esto usando un TypedDict:
class State(TypedDict): text:
str classification:
str entities: List[str] summary: strEste diseño de estado es fascinante porque refleja cómo procesamos la información los humanos. Cuando leemos un documento, mantenemos varias piezas de información simultáneamente: recordamos el texto original, entendemos qué tipo de documento es, anotamos nombres o conceptos importantes y formamos una comprensión concisa de sus puntos principales. Nuestra estructura de estado captura estos mismos elementos.
llm = ChatOpenAI(model=«gpt-4o-mini»,temperature=0)A continuación, inicializamos el LLM que queremos utilizar (en este caso, «gpt-4o-mini», pero puedes utilizar cualquier LLM que desees. Si trabajas con la API de OpenAI, tendrás que crear un token privado en su sitio web que te permita utilizarlo) con temperatura = 0. Temperatura = 0 en los LLM significa que el modelo elegirá siempre el token más probable en cada paso, haciendo que los resultados sean deterministas y consistentes. Esto conduce a respuestas más enfocadas y precisas, pero potencialmente menos creativas en comparación con ajustes de temperatura más altos que introducen más aleatoriedad en la selección de tokens.
Creación de las capacidades básicas de nuestro agente
Ahora crearemos las habilidades reales que utilizará nuestro agente. Cada una de estas capacidades se implementa como una función que realiza un tipo específico de análisis.
Primero, creemos nuestra capacidad de clasificación:
def classification_node(state: State):
''' Classify the text into one of the categories: News, Blog, Research, or Other '''
prompt = PromptTemplate(
input_variables=["text"],
template="Classify the following text into one of the categories: News, Blog, Research, or Other.\n\nText:{text}\n\nCategory:"
)
message = HumanMessage(content=prompt.format(text=state["text"]))
classification = llm.invoke([message]).content.strip()
return {"classification": classification}Esta función actúa como un bibliotecario experto que puede determinar rápidamente qué tipo de documento está mirando. Observa cómo utilizamos una plantilla de mensaje para dar instrucciones claras y coherentes a nuestro modelo de IA. La función toma nuestro estado actual (que incluye el texto que estamos analizando) y devuelve su clasificación.
A continuación, creamos nuestra capacidad de extracción de entidades:
def entity_extraction_node(state: State):
''' Extract all the entities (Person, Organization, Location) from the text '''
prompt = PromptTemplate(
input_variables=["text"],
template="Extract all the entities (Person, Organization, Location) from the following text. Provide the result as a comma-separated list.\n\nText:{text}\n\nEntities:"
)
message = HumanMessage(content=prompt.format(text=state["text"]))
entities = llm.invoke([message]).content.strip().split(", ")
return {"entities": entities}Esta función es como un lector atento que identifica y recuerda todos los nombres, organizaciones y lugares importantes mencionados en el texto. Procesa el texto y devuelve una lista de estas entidades clave.
Finalmente, implementamos nuestra capacidad de resumen:
def summarization_node(state: State):
''' Summarize the text in one short sentence '''
prompt = PromptTemplate(
input_variables=["text"],
template="Summarize the following text in one short sentence.\n\nText:{text}\n\nSummary:"
)
message = HumanMessage(content=prompt.format(text=state["text"]))
summary = llm.invoke([message]).content.strip()
return {"summary": summary}Esta función actúa como un editor experto que puede destilar la esencia de un documento en un resumen conciso. Toma nuestro texto y crea un resumen breve e informativo de sus puntos principales.
Uniéndolo todo
Ahora viene la parte más emocionante: conectar estas capacidades en un sistema coordinado:
workflow = StateGraph(State)
# Add nodes to the graph
workflow.add_node("classification_node", classification_node)
workflow.add_node("entity_extraction", entity_extraction_node)
workflow.add_node("summarization", summarization_node)
# Add edges to the graph
workflow.set_entry_point("classification_node") # Set the entry point of the graph
workflow.add_edge("classification_node", "entity_extraction")
workflow.add_edge("entity_extraction", "summarization")
workflow.add_edge("summarization", END)
# Compile the graph
app = workflow.compile()
¡Enhorabuena, acabamos de crear un agente!
Un recordatorio de cómo se ve:
Aquí es donde brilla el poder de LangGraph. No solo estamos recopilando diferentes capacidades, estamos creando un flujo de trabajo coordinado que determina cómo funcionan estas capacidades juntas. Piensa en ello como en la creación de una línea de producción para el procesamiento de información, donde cada paso se basa en los resultados de los anteriores.
La estructura que hemos creado le dice a nuestro agente que:
Empiece por entender con qué tipo de texto está tratando.
A continuación, identifique las entidades importantes dentro de ese texto.
Por último, crea un resumen que recoja los puntos principales.
Finaliza el proceso una vez que el resumen esté completo.
Ver a nuestro agente en acción
Ahora que hemos creado nuestro agente, es hora de ver cómo funciona con texto del mundo real. Aquí es donde la teoría se encuentra con la práctica, y donde podemos comprender realmente el poder de nuestro enfoque basado en gráficos. Probemos nuestro agente con un ejemplo concreto:
sample_text = """
OpenAI has announced the GPT-4 model, which is a large multimodal model that exhibits human-level performance on various professional benchmarks. It is developed to improve the alignment and safety of AI systems.
additionally, the model is designed to be more efficient and scalable than its predecessor, GPT-3. The GPT-4 model is expected to be released in the coming months and will be available to the public for research and development purposes.
"""
state_input = {"text": sample_text}
result = app.invoke(state_input)
print("Classification:", result["classification"])
print("\nEntities:", result["entities"])
print("\nSummary:", result["summary"])Cuando ejecutamos este código, nuestro agente procesa el texto a través de cada una de sus capacidades, y obtenemos el siguiente resultado:
Classification: News
Entities: ['OpenAI', 'GPT-4', 'GPT-3']
Summary: OpenAI's upcoming GPT-4 model is a multimodal AI that aims for human-level performance, improved safety, and greater efficiency compared to GPT-3.
Traducido:
Clasificación: Noticias
Entidades: ['OpenAI', 'GPT-4', 'GPT-3']
Resumen: El próximo modelo GPT-4 de OpenAI es una IA multimodal que pretende alcanzar un rendimiento a nivel humano, una mayor seguridad y una mayor eficiencia en comparación con GPT-3.
Analicemos lo que está sucediendo aquí, ya que demuestra maravillosamente cómo nuestro agente coordina sus diferentes capacidades para comprender el texto de manera integral.
En primer lugar, nuestro nodo de clasificación identificó correctamente que se trataba de un artículo de noticias. Esto tiene sentido dado el formato de estilo de anuncio del texto y el enfoque en los acontecimientos actuales. El agente reconoció las características de la redacción de noticias: información oportuna, presentación fáctica y enfoque en un acontecimiento específico.
A continuación, la capacidad de extracción de entidades identificó a los actores clave de esta historia: OpenAI como organización, y GPT-4 y GPT-3 como las entidades técnicas clave que se están discutiendo. Observa cómo se centró en las entidades más relevantes, filtrando los detalles menos importantes para darnos una idea clara de quién y de qué trata este texto.
Por último, la capacidad de resumen reunió toda esta comprensión para crear un resumen conciso pero completo. El resumen capta los puntos esenciales: el anuncio de GPT-4, sus mejoras clave con respecto a GPT-3 y su importancia. No se trata de una selección aleatoria de frases, sino de una destilación inteligente de la información más importante.
Comprender el poder del procesamiento coordinado
Lo que hace que este resultado sea particularmente impresionante no son solo los resultados individuales, sino cómo cada paso se basa en los demás para crear una comprensión completa del texto. La clasificación proporciona un contexto que ayuda a enmarcar la extracción de entidades, y ambos informan el proceso de resumen.
Piensa en cómo esto refleja la comprensión lectora humana. Cuando leemos un texto, naturalmente formamos una comprensión de qué tipo de texto es, anotamos nombres y conceptos importantes, y formamos un resumen mental, todo mientras mantenemos las relaciones entre estos diferentes aspectos de comprensión.
Aplicaciones prácticas y perspectivas
El ejemplo que hemos construido demuestra un patrón fundamental que puede aplicarse a muchos escenarios. Aunque lo usamos para analizar un artículo de noticias sobre IA, la misma estructura podría adaptarse para analizar:
Documentos de investigación médica, donde es crucial comprender el tipo de estudio, los términos médicos clave y los hallazgos principales. Documentos legales, donde es esencial identificar a las partes involucradas, las cláusulas clave y las implicaciones generales. Informes financieros, donde la comprensión del tipo de informe, las métricas clave y las principales conclusiones impulsan la toma de decisiones.
Comprender las limitaciones de nuestro agente
Es importante comprender que nuestro agente, aunque poderoso, opera dentro de los límites que hemos definido. Sus capacidades están determinadas por los nodos que hemos creado y las conexiones que hemos establecido entre ellos. Esto no es tanto una limitación como una característica: hace que el comportamiento del agente sea predecible y fiable.
En primer lugar, está la cuestión de la adaptabilidad. A diferencia de los humanos, que pueden ajustar de forma natural su enfoque cuando se enfrentan a nuevas situaciones, nuestro agente sigue una ruta fija a través de sus tareas. Si el texto de entrada contiene patrones inesperados o requiere un enfoque de análisis diferente, el agente no puede modificar dinámicamente su flujo de trabajo para manejar mejor estos casos.
Luego está el desafío de la comprensión contextual. Si bien nuestro agente puede procesar texto de manera efectiva, opera exclusivamente dentro del alcance del texto proporcionado. No puede recurrir a un conocimiento más amplio ni comprender matices sutiles como referencias culturales o significados implícitos que podrían ser cruciales para un análisis preciso. (Puedes superar esto con un componente de búsqueda en Internet si la información se puede encontrar en Internet).
El agente también se enfrenta a un desafío común en los sistemas de IA: el problema de la caja negra. Aunque podemos observar los resultados finales de cada nodo, no tenemos una visibilidad completa de cómo el agente llega a sus conclusiones. Esto dificulta la depuración de problemas o la comprensión de por qué el agente puede producir ocasionalmente resultados inesperados. (una excepción aquí es el uso de modelos de razonamiento como GPT-o1 o DeepSeek R1 que te muestran su forma de pensar, pero aún así no puedes controlarlo)
Por último, está la cuestión de la autonomía. Nuestro agente requiere una cuidadosa supervisión humana, sobre todo para validar sus resultados y garantizar su precisión. Como muchos sistemas de IA, está diseñado para aumentar las capacidades humanas en lugar de reemplazarlas por completo.
Estas limitaciones determinan cómo debemos utilizar y desplegar tales agentes en aplicaciones del mundo real. Comprenderlas nos ayuda a diseñar sistemas más eficaces y a saber cuándo la experiencia humana debe formar parte del proceso.
Nota: Agradecemos a Nir Diamant su colaboración en este artículo.
Cada vez tus artículos me sorprenden más.. ¡Sigue así!
Este post hace que la inteligencia artificial suene accesible para todos. Me encanta cómo explica el proceso de crear tu propio agente de IA de manera sencilla y clara, sin complicaciones técnicas.